
OpenJDK 源码阅读之 Java 输入输出(I/O) 之 字节流输出
标签(空格分隔): 源代码阅读 Java 封神之路
字节流输出
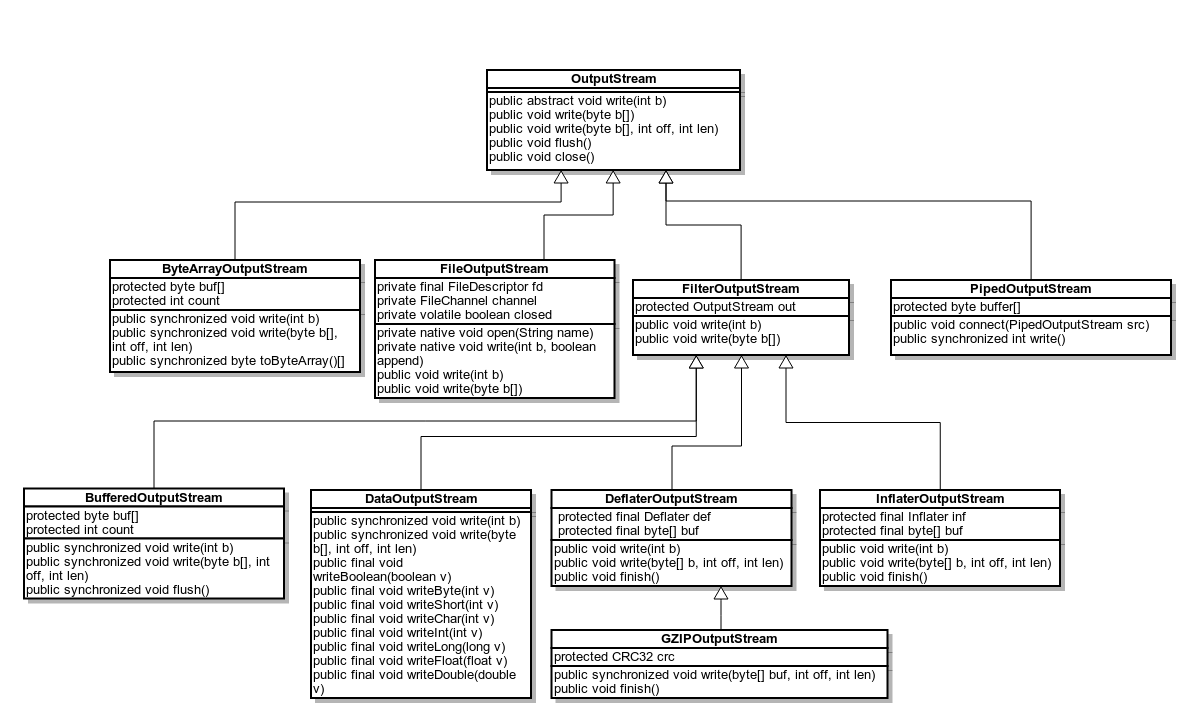
图1 Java 字节输出类
- OutputStream
OutputStream是所有字节输出类的超类,这是个抽象类,需要实现其中定义的 write 函数,才能有实用的功能。
public abstract void write(int b) throws IOException;
其它方法都是在 write 的基础上实现的。例如这个多态的 write :
public void write(byte b[], int off, int len)
throws IOException {
if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}
- FileOutputStream
FileOutputStream 会将内容输出到 File 或者 FileDescriptor, 此类是按照字节输出,如果想按照字符输出,可以使用 FileReader 类。
构造器中,需要指明输出的文件:
public FileOutputStream(File file, boolean append)
throws FileNotFoundException
{
String name = (file != null ? file.getPath() : null);
SecurityManager security = System.getSecurityManager();
if (security != null) {
security.checkWrite(name);
}
if (name == null) {
throw new NullPointerException();
}
this.fd = new FileDescriptor();
this.append = append;
fd.incrementAndGetUseCount();
open(name, append);
}
写入操作是一个 native 函数,与操作系统相关。
private native void write(int b, boolean append) throws IOException;
如果对比一下字节输入类,你会发现输入和输出在实现上有很大的相似性,它们是对称的。
- ByteArrayOutputStream
ByteArrayOutputStream 会将数据写入字节数组中, 可以通过 toByteArray,toString 得到这些数据。
protected byte buf[];
初始化时,可以指定这个数组的大小:
public ByteArrayOutputStream(int size) {
if (size < 0) {
throw new IllegalArgumentException("Negative initial size: "
+ size);
}
buf = new byte[size];
}
写入时,会写入这个数组。write 会先保证数组的大小,如果不够用,还会自动进行扩充。
public synchronized void write(int b) {
ensureCapacity(count + 1);
buf[count] = (byte) b;
count += 1;
}
- FilterOutputStream
所有有过滤功能的类的基类,例如,对输出流进行转化,或者添加新的功能。初始化时,需要提供一个底层的流,用于写入数据,FilterOUtputStream 类的所有方法都是通过调用这个底层流的方法实现的。
初始化时,
protected OutputStream out;
public FilterOutputStream(OutputStream out) {
this.out = out;
}
写入时:
public void write(int b) throws IOException {
out.write(b);
}
- BufferedOutputStream
BufferedOutputStream 是 FilterOutputStream 的子类,提供缓冲功能,所以,你不用每写入一个字节都要调用操作系统的 write 方法,而是积累到缓冲区,然后一起写入。
缓冲区就是一个字节数组,在构造器中被初始化。
protected byte buf[];
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
当调用 write(b) 时,并不真正写入,而是将要写入的数据存放在缓冲区内,等缓冲区满后,一次性写入数据。
public synchronized void write(int b) throws IOException {
if (count >= buf.length) {
flushBuffer();
}
buf[count++] = (byte)b;
}
- DataOutputStream
DataOutputStream 可以按 Java 的基本类型写入数据。写入的原理是,将基本类型数据中的字节分离出来,然后将这些字节写入。例如:
public final void writeBoolean(boolean v) throws IOException {
out.write(v ? 1 : 0);
incCount(1);
}
boolean 类型就是按照 0/1 的方式写入的。
public final void writeShort(int v) throws IOException {
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(2);
}
short 是两个字节,需要将其中的两个字节分离出来,分别写入,incCount 加了2. writeChar 同理,因为它也是写入两个字节。
浮点数比较特殊,没法直接分离出各个字节,要调用 Float 的一个静态方法,把浮点数转化成四个字节,再通过 writeInt 写入。floatToInitBits 会调用一个 native 方法, 按照 IEEE 754 标准,完成其主要功能。
public final void writeFloat(float v) throws IOException {
writeInt(Float.floatToIntBits(v));
}
- PipedOutputStream
管道输出流可以与一个管道输入流相关联,关联后,共用一个缓冲区,输出流写入数据,输入流读取数据,二者应该处于不同线程,否则可能出现死锁。
原理上一篇文章在介绍 PipedInputStream 时,已经阐述。
另外,我觉得在这里,有必要说一下那几个用于压缩和解压缩的类,实现就不说了,就讲下他们的功能与关系。
JAVA IO 压缩与解压缩
- InflaterInputStream: 用于解压 deflate 格式的压缩数据,底层流为压缩后的数据,read 返回解压后的数据。
- InflaterOutputStream: 用于解压 deflate 格式的压缩数据,底层流为压缩后的数据,write 写入解压后的数据。
- DeflaterInputStream: 用于压缩成 deflate 格式的数据,底层流为未压缩数据,read 返回压缩后的数据。
DeflaterOutputStream: 用于压缩成 deflate 格式的数据,底层流为未压缩数据,write 写入压缩后的数据。
GZIPInputStream: 用于解压 GZip 格式的压缩数据,底层流为压缩后的数据,read 返回解压后的数据。它是 InflaterInputStream 的子类。
GZIPOutputStream: 用于压缩成 Gzip格式的数据,底层流为未压缩数据,write 写入压缩后的数据。是 DeflaterOutputStream 的子类(注意不是InflaterOutputStream) 。
不得不说,这个API设计的真是太反直觉了。GZIP 格式的解压和压缩一个是 GZIPInputStream,一个是 GZIPOutputStream。而 deflate 格式的解压和压缩,一个是 InflaterInputStream/InflaterOutputStream,另一个是 DeflaterInputStream/DeflaterOutputStream。当同时需要对 gzip 和 deflate 压缩和解压缩时,就感觉,真是反直觉。