
C语言中的int类型的范围是由什么决定的
在 K&R 经典教材 The C Programming Language 的2.2节中,对 int 类型是这样描述的
an integer, typically reflecting the natural size of integers on the host machine
意思是反映了机器整数类型的 natural size,可是,
这个 natural size 又是什么意思呢?
书中后来在谈到 short, int, long 的关系时,又说,这些类型由编译器根据机器自由选择合适的大小,但是 short 和 int 至少 16 位,long 至少 32 位。
这里的问题是
编译器是根据什么决定类型大小呢?
后面书中又提到,这些类型啊,在<limits.h>中都有,我就在ubuntu下查看了 /usr/include/limits.h,里面确实提到
/* Minimum and maximum values a `signed int' can hold. */
# define INT_MIN (-INT_MAX - 1)
# define INT_MAX 2147483647
但是,这也是一种定义,还是没有说出为什么,我现在想知道的是
为什么
于是,我想起了那些年扫过的 《深入理解计算机系统》,英文名叫 Computer Systems: A Programmer's Perspective,速查之!
在2.1节的开头提到,字节(byte)是最小可寻址单位,大多数计算机使用8位的块。 啊,8位,那位又是什么呢?嗯,位是一种存储结构,一个位只能存储0或者1。
后面2.1.2节中提到
每台计算机都有一个字长(word size),指明了整数和指针数据的 nominal size。
指针是什么,指针就是内存中的地址啊,假如字长为w位,那么地址的数目就是2^w个啊,那一个地址代表多大内存呢?
前面说了,字节(byte)是最小可寻址单位,所以一个地址代表一个字节。当字长是w位时,地址数目2^w个,共有2^w个字节的内存空间。
如果计算机字长为32,即传说中的32位计算机,那么它可以表示的内存空间就是 2^32 个字节,这就是传说中的4G啊!
现在我们是由字长32位,也就是整数的大小32位,推出了内存空间4G。我现在在想:
是不是一开始是决定内存空间是4G,所以才定下了字长32位的规矩,由此,机器的natural size是32位, 所以,编译器才将C语言中int类型才是32位呢?
可是我没有证据啊!
没有证据就尝试推理一下吧。
我们知道32位机器是由16位机器扩展来的,那为什么要扩展机器字长呢?这个问题原因之一,我们刚才已经解释过了,如果不扩展,那么机器最大寻址空间就比较小,即使我给你一个大内存,你也用不上啊。这可能这也今天我们从32位转到64位的原因吧。
所以,现在我们明白了,由于我们想要更大的内存地址空间,所以就将字长从16位提升为32位,而字长代表着指针和整数类型的大小,所以最终整数类型就是32位了。
不过这里还有不少问题。
字长这东西只是个抽象的概念,方便我们描述机器的一些属性,暂时不谈。
先说指针。对于机器来说,哪里有什么指针的概念,指针是C语言中的东西,编译成汇编后就没指针这个概念了。但是,指针表示的是内存的地址,而内存的地址又和机器中的什么部件相关呢?
再说整数。到汇编这一层,整数的概念还存在吗?整数的概念应该是和汇编中的算术指令相关,那么算术指令又和机器中的什么部件相关呢?
最后,指针是表示内存地址啊,我们有了更大内存,那么内存地址需要更长的位来表示是可以理解的,可是,这关你整数什么事啊?我内存地址32位,整数16位不行吗?
其实,总的问题就是
字长都与机器的什么部件相关
要解释这个问题,我们发现自己不由自主地来到了《深入理解计算机系统》的第四章“处理器体系结构”。
这一章以一种叫Y86的处理器介绍了处理器体系结构的方方面面。首先介绍了寄存器,寄存器是一种存储部件,存储什么?存储信息,存储信息用来做什么呢?用来计算。我们在C语言中使用一个简单的加法计算,在处理器这一层,就需要使用寄存器来帮助我们计算。我们把一个简单的C语言编译成汇编看看。
/* test_add.c */
#include <stdio.h>
int main(void) {
int a = 1;
int b = 2;
int c = a + b;
return 0;
}
使用 GCC 编译一下
gcc -S test_add.c -o test_add.s
然后查看一下主要代码。
movl $1, -12(%ebp)
movl $2, -8(%ebp)
movl -8(%ebp), %eax
movl -12(%ebp), %edx
addl %edx, %eax
movl %eax, -4(%ebp)
其中的 ebp eax edx 就是寄存器。
可以看出,数据先放到栈里,再从栈里放到寄存器里,然后再进行加法运算,最后再从寄存器里把结果放回栈里。
下面的图是书中给出的一个处理器的抽象视图:
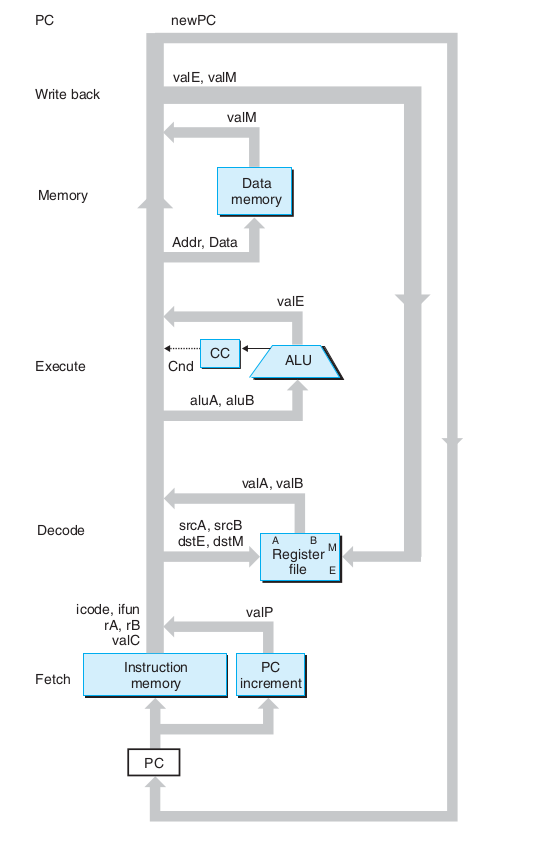
栈是什么?栈是一种抽象概念,这里的栈就是指内存。
书里说了,在32位计算机中,这些寄存器的大小就是32位。可见,
字长与寄存器大小一样
除此之外,我们可以看到,需要计算的时候,movl 指令将数据从内存中放到寄存器里,由于内存和寄存器是不同的部件,所以需要一个部件来传递数据,这种部件叫做数据总线。
寄存器的大小与字长相同,那么这种数据总线每次能传送的数据也应该与字长相同,所以:
字长与数据总线宽度一样
另外,再想像一下,你想要从内存中取数据出来,总要告诉内存你取的是哪个地址的数据吧,所以,“地址”这个数据也是要从某个地方传送到内存的。只要传递,就需要有部件支持,这个部件叫做地址总线,地址总线传递地址,地址大小与字长一样,那么,我们可以知道:
字长与地址总线宽度一样
好了,到了这里,我们的分析就差不多了,总结一下:
我们由C语言中int类型的大小,得到了字长这个概念,又从字长这个概念寻找了与其相关的一些机器部件的属性。到现在为此,与字长相关的有:
- int 类型
- 指针(即内存地址)
- 寄存器
- 数据总线
- 地址总线
在 Wikipedia 的 Word(computer_architecture)#Tableofword_sizes)词条中,我们可以看到自1837年以来,一系列计算机体系结构中与字长相关的一些属性的变化。
我们再想想,为什么要将这么多种部件都设置成相同长度?我想,可能是因为计算机内部实在太复杂了,各个部件之间需要紧密地配合,共同完成复杂的任务。尤其是数据,需要在各个部件之间传递,如果这些部件之间大小不统一,就会增加机器的复杂度,由于,我们将这些部件大小尽可能统一,进而提出字长这种概念来描述计算机的重要性质。
到这里,我们再想一下,字长这个概念和这么多部件相关,那么确定字长多大应该不仅仅与内存大小有关系。比如字长代表寄存器的大小,寄存器与机器的运算直接相关,字长变大后,每次能参与计算的值也相应变大,以前我们计算两个很大的数的和时,可能需要动用好几个寄存器,现在咱字长大了,寄存器也大了,只需要两个寄存器就可以了。
由此可见,字长的确定是一个综合的考量,代表着计算机计算,存储能力的全面提升。
文章结束了,思考永不停止。