
-
- 2014-07-12
-
- 2014-07-11
OpenJDK 源码阅读之 Java 输入输出(I/O) 之 字节流输入
标签(空格分隔): 源代码阅读 Java 封神之路
Java 的输入输出总是给人一种很混乱的感觉,要想把这个问题搞清楚,必须对各种与输入输出相关的类之间的关系有所了解。只有你了解了他们之间的关系,知道设计这个类的目的是什么,才能更从容的使用他们。
我们先对 Java I/O 的总体结构进行一个总结,再通过分析源代码,给出把每个类的关键功能是如何实现的。
Read More ... -
- 2014-05-28
OpenJDK 源码阅读之 LinkedList
概要
- 类继承关系
Read More ...java.lang.Object java.util.AbstractCollection<E> java.util.AbstractList<E> java.util.AbstractSequentialList<E> java.util.LinkedList<E> -
- 2014-05-27
开始OpenJDK源代码阅读
在阅读了一周的 OpenJDK 源代码后,我才写这篇文章。因为除非你已经开始阅读,否则是不知道自己是不是应该读下去的。所以,不要贸然说自己要干嘛,先做一段时间,觉得感觉还好,再决定做下去。
这一周,主要是看
Read More ...java.util中和容器相关的几个文件,虽然还没看太多,但是已经有一些收获了。看到了以前学过的数据结构在Java的标准库中是如何被实现的。也明白了平时使用的一些类的原理是什么。另外,由于最近在看 《Java编程思想》,也能把书中讲的和标准库的源代码对应起来,感觉还不错。还有一个收获就是明白了,基础越扎实,阅读源代码收获也越大,否则根本就看不出一些设计的初衷是什么。之前看到源代码中一些编写程序的方式,我觉得没有必要那样写,后来看《Java编程思想》,才知道为什么会这样写。也有一些是我觉得可以从源代码中学习的东西,从《Java编程思想》中看到,标准库中的编写方式有些是历史遗留问题,不得不那么写,而不是说我们写的时候,也要那样做。这就是说不要迷信那些你不明白的东西,即使他们看起来很权威。 -
- 2014-05-26
OpenJDK 源代码阅读之 TreeMap
概要
- 类继承关系
java.lang.Object java.util.AbstractMap<K,V> java.util.HashMap<K,V>- 定义
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable- 要点
1) 基于 NavigableMap 实现的红黑树 2) 按
Read More ...natrual ordering或者Comparator定义的次序排序。 3) 基本操作containsKey,get,put有log(n)的时间复杂度。 4) 非线程安全 -
- 2014-05-25
OpenJDK 源代码阅读之 HashMap
概要
- 类继承关系
java.lang.Object java.util.AbstractMap<K,V> java.util.TreeMap<K,V>- 定义
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, Serializable- 要点
1) 与 Hashtable 区别在于:非同步,允许
Read More ...null2) 不保证次序,甚至不保证次序随时间不变 3) 基本操作 put, get 常量时间 4) 遍历操作 与 capacity+size 成正比 5) HashMap 性能与capacity和load factor相关,load factor是当前元素个数与capacity的比值,通常设定为0.75,如果此值过大,空间利用率高,但是冲突的可能性增加,因而可能导致查找时间增加,如果过小,反之。当元素个数大于capacity * load_factor时,HashMap会重新安排 Hash 表。因此高效地使用HashMap需要预估元素个数,设置最佳的capacity和load factor,使得重新安排 Hash 表的次数下降。 -
- 2014-05-24
OpenJDK 源码阅读之 ArrayList
概要
- 类继承关系
java.lang.Object java.util.AbstractCollection<E> java.util.AbstractList<E> java.util.ArrayList<E>- 定义
Read More ...public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { } -
- 2014-05-23
OpenJDK 源代码阅读之 String
概要
- 类继承关系
java.lang.Object java.lang.String- 定义
public final class String extends Object implements Serializable, Comparable<String>, CharSequence- 要点
一旦创建就不可改变
实现
- storage
/** The value is used for character storage. */ private final char value[];可以看出
String中的数据是如何存储的。- 初始化
public String(String original) { this.value = original.value; this.hash = original.hash; }可以看出使用
String类型初始化,新String实际上与原来的String指向同一块内存。public String(char value[]) { this.value = Arrays.copyOf(value, value.length); }如果用
char[]初始化,可以看出,新分配了内存,并复制,保证了两者相互独立,只是内容相同。public String(StringBuffer buffer) { synchronized(buffer) { this.value = Arrays.copyOf(buffer.getValue(), buffer.length()); } }注意用
StringBuffer初始化时,对同一buffer是线程安全的,即初始化String的过程中,其它线程不会改变buffer的内容。另外,能告诉我下面这段代码是怎么回事么?
public String(StringBuilder builder) { this.value = Arrays.copyOf(builder.getValue(), builder.length()); }为啥这次不同步了呢?
Read More ... -
- 2014-05-22
OpenJDK 源代码阅读之 HashSet
概要
- 类继承关系
java.lang.Object java.util.AbstractCollection<E> java.util.AbstractSet<E> java.util.HashSet<E>- 定义
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, Serializable- 要点
- 不保证元素次序,甚至不保证次序不随时间变化
- 基本操作(add, remove, contains, size)常量时间
- 迭代操作与当前元素个数加底层容量大小成正比
- 不保证同步
思考
- 总体实现
底层是用
HashMap实现的,Set中的数据是HashMap的key,所有的key指向同一个value, 此value定义为:// Dummy value to associate with an Object in the backing Map private static final Object PRESENT = new Object();再看一下
add,大概就能明白了/** * Adds the specified element to this set if it is not already present. * More formally, adds the specified element <tt>e</tt> to this set if * this set contains no element <tt>e2</tt> such that * <tt>(e==null ? e2==null : e.equals(e2))</tt>. * If this set already contains the element, the call leaves the set * unchanged and returns <tt>false</tt>. * * @param e element to be added to this set * @return <tt>true</tt> if this set did not already contain the specified * element */ public boolean add(E e) { return map.put(e, PRESENT)==null; }- load factor
public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); }初始化中,注意使用的
Read More ...HashMap的 load factor 设置为 0.75,如果太小,就设置成 16. 为什么要 0.75 呢? 有什么依据吗? -
- 2014-05-21
OpenJDK 源码阅读之 LinkedList
定义
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable { }盲点
- serialVersionUID
private static final long serialVersionUID = 876323262645176354L;序列化版本号,如果前一版本序列化后,后一版本发生了很大改变,就使用这个号告诉虚拟机,不能反序列化了。
问题
- writeObject
比例一下
ArrayList与LinkedList中的 writeObjectprivate void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ // Write out element count, and any hidden stuff int expectedModCount = modCount; s.defaultWriteObject(); // Write out array length s.writeInt(elementData.length); // Write out all elements in the proper order. for (int i=0; i<size; i++) s.writeObject(elementData[i]); if (modCount != expectedModCount) { throw new ConcurrentModificationException(); } }private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // Write out size s.writeInt(size); // Write out all elements in the proper order. for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item); }注意后者没有检查
modCount,这是为什么呢?之前看ArrayList的时候觉得是为线程安全考虑的,可是现在为什么又不检查了呢?虽然两个文件的注释中都说到,如果有多个线程操作此数据结构,应该从外部进行同步。但是一个检查,一个不检查是几个意思呀?思考
- 维护数据结构一致性
private void linkFirst(E e) { final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; }注意代码第
5行对f的检查,6行对last的调整。一定要细心,保证操作后,所有可能涉及的数据都得到相应更新。- 隐藏实现
public E getFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return f.item; }注意返回的是数据,而不是
Read More ...Node,外部根本不需要知道Node的存在。 另外,为什么f == null要抛出异常而不是返回null? -
- 2014-01-24
- 源代码阅读
wsgiref 源代码分析
wsgiref
wsgiref 是Python标准库给出的 WSGI 的参考实现。
WSGI是Python Web 开发中为服务器程序和应用程序设定的标准,满足这一标准的服务器程序和应用程序可以配合使用。我在上一篇博文《WSGI简介》中对此有详细的介绍。在阅读wsgiref源代码之前,一定要对WSGI有一定了解。
WSGI 在 PEP 333 中描述,但是只靠阅读PEP 333 可能在理解上还是不够深入,所以阅读官方给出的参考实现是很有必要的。阅读完这份源代码后,不仅有利于对WSGI的理解。而且会让你对服务端程序如何对客户端请求有一个直观的理解,从相对底层的socket监听请求,到上层对HTTP请求的处理。
当然,这只是对WSGI的参考实现,目的是为了描述清楚WSGI,而不是真正用在产品中。如果想对Python Web开发中服务器端的实现有更广泛,更深入的理解,需要进一步阅读Python常用框架的源代码。
wsgiref 源代码分析
wsgiref 源代码可以在 pypi wsgiref 0.1.2 下载。另外,我在阅读的过程中作了大量注释,包含模块介绍,调用层次关系,demo的运行结果,等 等,还包含了阅读过程中制作的思维导图。GitHub地址注释版wsgiref。
结构
上图描述了wsgiref的所有模块及模块间的调用关系,可以看出,wsgiref有以下模块:
simple_server
这一模块实现了一个简单的 HTTP 服务器,并给出了一个简单的 demo,运行:python simple_server.py
会启动这个demo,运行一次请求,并把这次请求中涉及到的环境变量在浏览器中显示出来。
- handlers
simple_server模块将HTTP服务器分成了 Server 部分和Handler部分,前者负责接收请求,后者负责具体的处理, 其中Handler部分主要在handlers中实现。 - headers
这一模块主要是为HTTP协议中header部分建立数据结构。 - util
这一模块包含了一些工具函数,主要用于对环境变量,URL的处理。 - validate
这一模块提供了一个验证工具,可以用于验证你的实现是否符合WSGI标准。
simple_server
Read More ... -
- 2013-11-21
- 源代码阅读
web.py 项目之 googlemodules
项目说明
项目来自 webpy.org, 这是一个真实的在线上运行的 项目: Google Modules, 可以上传,下载, 一些模块,还有一些评分,打标签等等功能。(不过这网站挺奇怪的。。。)
目录树
src/ ├── application.py ├── forum.py ├── config_example.py ├── INSTALL ├── LICENCE ├── app │ ├── controllers │ ├── helpers │ ├── models │ └── views ├── app_forum │ ├── controllers │ ├── models │ └── views ├── data ├── public │ ├── css │ ├── img │ │ └── star │ ├── js │ └── rss ├── scripts └── sql 18 directories终于遇到个稍微大一点的项目了,要好好看看。
从目录上看,整个项目分成两个部分,app 和 app_forum,每个部分都使用了 典型的MVC结构,将app分成 controllers, models, views 三大部分。
另外,网站使用的 css, js 文件,图片,也都统一放在了public目录下。
INSTALL 文件描述了如何安装部署项目, 包括在哪里下载项目,哪里下载web.py,如何 配置 lighttpd, 如何配置项目。
config_example.py 文件给了一个配置文件模板,按自己的需要修改其中内容,最后 把文件名改为 config.py 就可以了,其中包括对数据的配置,调试,缓存的开启等等。
LICENCE 文件描述了项目使用的开源协议: GPLv3。
项目使用的脚本放在scripts目录下,创建数据库使用的文件放在了sql目录下。
代码统计
先看看代码统计
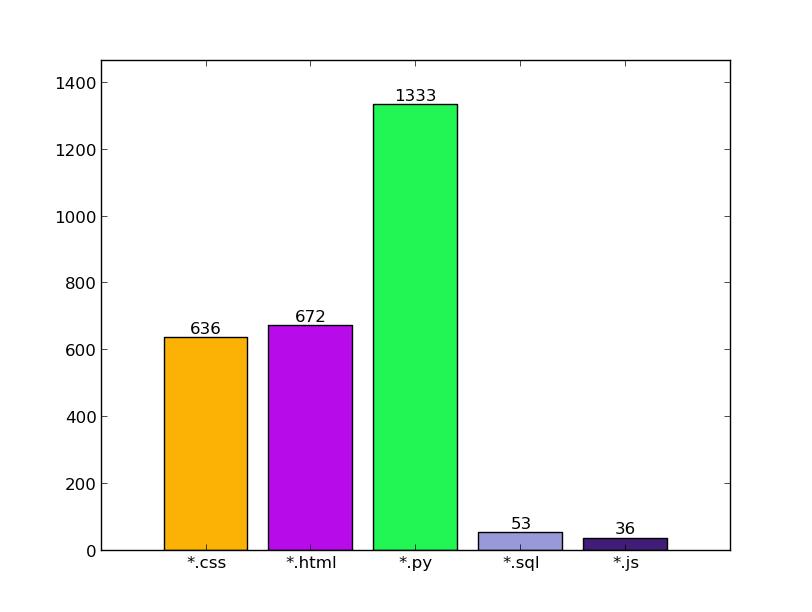
application 模块
application.py
#!/usr/bin/env python # Author: Alex Ksikes # TODO: # - setup SPF for sendmail and # - emailerrors should be sent from same domain # - clean up schema.sql # - because of a bug in webpy unicode search fails (see models/sql_search.py) import web import config import app.controllers from app.helpers import custom_error import forum urls = ( # front page '/', 'app.controllers.base.index', '/page/([0-9]+)/', 'app.controllers.base.list', # view, add a comment, vote '/module/([0-9]+)/', 'app.controllers.module.show', '/module/([0-9]+)/comment/', 'app.controllers.module.comment', '/module/([0-9]+)/vote/', 'app.controllers.module.vote', # submit a module '/submit/', 'app.controllers.submit.submit', # view author page '/author/(.*?)/', 'app.controllers.author.show', # search browse by tag name '/search/', 'app.controllers.search.search', '/tag/(.*?)/', 'app.controllers.search.list_by_tag', # view tag clouds '/tags/', 'app.controllers.cloud.tag_cloud', '/authors/', 'app.controllers.cloud.author_cloud', # table modules '/modules/(?:by-(.*?)/)?([0-9]+)?/?', 'app.controllers.all_modules.list_by', # static pages '/feedback/', 'app.controllers.feedback.send', '/about/', 'app.controllers.base.about', '/help/', 'app.controllers.base.help', # let lighttpd handle in production '/(?:css|img|js|rss)/.+', 'app.controllers.public.public', # canonicalize /urls to /urls/ '/(.*[^/])', 'app.controllers.public.redirect', # mini forum app '/forum', forum.app, '/hello/(.*)', 'hello', # site admin app # '/admin', admin.app, ) app = web.application(urls, globals()) custom_error.add(app) if __name__ == "__main__": app.run()可以看出,这是 application 部分的入口,这个模块仅仅是定义了各个请求的处理方式, 并完成程序的启动,所有的实现均不在这里出现,而是通过
import导入,特别需要 注意urls最后定义的/forum和/admin使用了子程序,而不是通过之前的字符串 实现映射。还需要注意对静态文件,即css,js,img,rss文件的单独处理。所有这些都与之前分析过的那些小项目不同,回想起我之前写的 BlogSystem, 所有的处理实现都放在 同一个文件中,导致最后一个文件居然 700多行,真是让人潸然泪下。。。 而且之前也不知道使用子程序,所有处理都堆在一起。看来读完这份源代码,真应该重构一 下了。
app 模块
app/ ├── models # 数据模块,MVC中的 M ├── views # 显示模块,MVC中的 V ├── controllers # 控制模块,MVC中的 C └── helpers # 辅助模块,实现辅助功能 4 directoriescontrollers 模块
controllers/ ├── base.py # 对基本页面,如网站主页,关于网页,帮助等的处理 ├── all_modules.py # 显示全部模块 ├── module.py # 对模块页面的处理 ├── search.py # 对搜索模块功能处理 ├── submit.py # 对提交模块的处理 ├── author.py # 查看模块作者信息 ├── cloud.py # 对标签云页面进行处理 ├── feedback.py # 处理反馈信息 └── public.py # 对静态文件的处理这个模块主要是对请求处理的实现,在
urls里定义的那些映射关系, 很多被映射到这里。实现过程中,调用 models 模块对数据操作,再送入 views 模块通过模板引擎显示数据内容。
models 模块
models/ ├── comments.py # 对评论数据的处理 ├── modules.py # 对模块数据的处理 ├── rss.py # 对 rss 订阅的处理 ├── sql_search.py # 对搜索的数据处理 ├── submission.py # 对用户提交内容的处理 ├── tags.py # 对标签内容的数据处理 └── votes.py # 对用户投票的数据处理这个模块直接调用 web.py 的db模块对数据库进行操作,对数据库的连接在 config.py 中 已经完成。这里完成数据的获取,处理,返回。可以看出,对不同种类的数据又分成了 很多小的模块。
Read More ... -
- 2013-11-18
- 源代码阅读
web.py 项目之 blog
目录树
src/ ├── blog.py ├── model.py ├── schema.sql └── templates ├── base.html ├── edit.html ├── index.html ├── new.html └── view.html 1 directory, 8 files项目说明
项目来自 webpy.org, 主要实现一个基于web的博客系统,实现了基本的增删查改。
结构分析
控制模块
控制模块包括 blog.py
Read More ...""" Basic blog using webpy 0.3 """ import web import model ### Url mappings urls = ( '/', 'Index', '/view/(\d+)', 'View', '/new', 'New', '/delete/(\d+)', 'Delete', '/edit/(\d+)', 'Edit', ) -
- 2013-11-17
- 源代码阅读
web.py 项目之 todolist
目录树
. └── src ├── model.py ├── schema.sql ├── templates │ ├── base.html │ └── index.html ├── todo.py 2 directories, 8 files项目说明
项目来自 webpy.org, 主要实现一个基于web的 todolist,就是可以添加删除一些任务。 非常简单
结构分析
控制模块
控制模块只有todo.py
Read More ...""" Basic todo list using webpy 0.3 """ import web import model ### Url mappings urls = ( '/', 'Index', '/del/(\d+)', 'Delete' ) -
- 2013-11-14
- 源代码阅读
web.py 项目之 skeleton
skeleton 是 web.py 官网上给出的一个最简单的项目结构示例。
目录树
. └── src ├── code.py ├── config.py ├── db.py ├── sql │ └── tables.sql ├── templates │ ├── base.html │ ├── item.html │ └── listing.html └── view.py 3 directories, 9 files结构分析
控制模块
#code.py import web import view, config from view import render urls = ( '/', 'index' ) class index: def GET(self): return render.base(view.listing()) if __name__ == "__main__": app = web.application(urls, globals()) app.internalerror = web.debugerror app.run()code模块作为入口:- app 的创建与启动
- url 与 处理类的映射与处理入口
但是,具体的处理并不在这里实现。而是放在了
view模块中。这一模块是MVC中的C吗?显示模块
#view.py import web import db import config t_globals = dict( datestr=web.datestr, ) render = web.template.render('templates/', cache=config.cache, globals=t_globals) render._keywords['globals']['render'] = render def listing(\**k): l = db.listing(\**k) return render.listing(l)从这里可以看出
view模块- 与模板关联
- 从数据库中取数据,然后发给模板
我们再来看看模板:
<!-- templates/base.html --> $def with (page, title=None) <html><head> <title>my site\ $if title: : $title\ </title> </head><body> <h1><a href="/">my site</a></h1> $:page </body></html>base.html是所有模块的公共部分,每个模块只需要提供 它的page,即内容就可以了。<!-- templates/listing.html --> $def with (items) $for item in items: $:render.item(item)这一模块是MVC中的V吗数据操作
数据库操作分三部分
- sql/tables.sql 数据库表定义
- config.py 数据库连接
- db.py 数据库操作
/* tables.sql */ CREATE TABLE items ( id serial primary key, author_id int references users, body text, created timestamp default current_timestamp );#config.py import web DB = web.database(dbn='mysql', db='skeleton', user='root', pw='xx') cache = False# db.py import config def listing(\**k): return config.DB.select('items', **k)这是MVC中的M吗这是 web.py 中最基本的一个项目结构。应该是使用的MVC设计模式。但是 因为程序本身不大,还体会不到 MVC 的好处。
Read More ... -
- 2013-11-14
- 源代码阅读
分模块测试
application.py
对 application.py 的测试,调用命令:
python test/application.pytest_reloader(self)
def test_reloader(self): write('foo.py', data % dict(classname='a', output='a')) import foo app = foo.app self.assertEquals(app.request('/').data, 'a') # test class change time.sleep(1) write('foo.py', data % dict(classname='a', output='b')) self.assertEquals(app.request('/').data, 'b') # test urls change time.sleep(1) write('foo.py', data % dict(classname='c', output='c')) self.assertEquals(app.request('/').data, 'c')总的来说,这个过程会生成一个 foo.py 文件
import web urls = ("/", "a") app = web.application(urls, globals(), autoreload=True) class a: def GET(self): return "a"这是一个典型的 web 服务端应用程序,表示对
/发起GET请求时,会调用class a中的GET函数,测试就是看看 web.application 是否可以正常完成任务,即是否可以正确返回"a"下面详细看代码。
首先使用
write生成了一个foo.py程序:write('foo.py', data % dict(classname='a', output='a'))write 源代码:
def write(filename, data): f = open(filename, 'w') f.write(data) f.close()data 定义: ```python data = """ import web
urls = ("/", "%(classname)s") app = web.application(urls, globals(), autoreload=True)
class %(classname)s: def GET(self): return "%(output)s"
""" ```
data相当于一个小型 web 程序的模板,类名和返回值由 一个dict指定,生成一个字符串,由write生成文件。下面是类别和返回值为
a时的foo.pyimport web urls = ("/", "a") app = web.application(urls, globals(), autoreload=True) class a: def GET(self): return "a"测试的方式采用
TestCase中的assertEquals函数,比较 实际值与预测值。import foo app = foo.app self.assertEquals(app.request('/').data, 'a')app.request('/')会得到一个Storage类型的值:<Storage {'status': '200 OK', 'headers': {}, 'header_items': [], 'data': 'a'}>其中的
data就是foo.py中GET返回的值。我对这个
app.request('/')是比较困惑的。以foo.py为例, 之前写程序时,一般是有一个这样的程序:import web urls = ("/", "a") app = web.application(urls, globals(), autoreload=True) class a: def GET(self): return "a" if __name__ == "__main__": app.run()然后在浏览器中请求
0.0.0.0:8080/。 而在request之前,也没看到run啊,怎么就能request回 数据呢,而且通过上述代码运行后,程序会一直运行直到手动关闭, 而request的方式则是测试完后,整个程序也结束了。所以,下一部,想比较一下
application.run和application.request的不同。我们只看关键部分,即返回的值是如何被设值的。
在
web.application.request中:def request(self, localpart='/', method='GET', data=None, host="0.0.0.0:8080", headers=None, https=False, **kw): ... response = web.storage() def start_response(status, headers): response.status = status response.headers = dict(headers) response.header_items = headers response.data = "".join(self.wsgifunc()(env, start_response)) return response上述代码中
self.wsgifunc()(env, start_response)比较另人困惑, 我还以为是调用函数的新方式呢,然后看了一下wsgifunc的代码, 它会返回一个函数wsgi,wsgi以(env, start_response)为参数。 在wsgi内部,又会调用handle_with_processors,handle_with_processors会再调用handledef handle(self): fn, args = self._match(self.mapping, web.ctx.path) return self._delegate(fn, self.fvars, args)测试了一下,
self._match()会得到类名,self._delegate会 得到返回的字符串,即GET的返回值。进入
self._delegate, 会最终调用一个关键函数handle_class:def handle_class(cls): meth = web.ctx.method if meth == 'HEAD' and not hasattr(cls, meth): meth = 'GET' if not hasattr(cls, meth): raise web.nomethod(cls) tocall = getattr(cls(), meth) return tocall(\*args)参数
cls值为foo.a,meth会得到方法名GET, 然后tocall会得到函数a.GET, 至此,我们终于得以调用,GET函数,得到了返回的字符串。从整个过程可以看出,没有启动服务器的代码,只是不断地调用 函数,最终来到
Read More ...GET函数。 -
- 2013-11-14
- 源代码阅读
-
- 2013-11-14
- 源代码阅读
-
- 2013-11-14
- 源代码阅读
-
- 2013-11-14
- 源代码阅读
目录文件说明
README
如何运行测试文件,包含全部测试及分模块测试
调用
$ python test/alltests.py运行全部测试
调用
$ python test/db.py运行db模块测试
alltest.py
运行全部测试入口,调用
webtest模块完成测试# alltest.py if __name__ == "__main__": webtest.main()webtest.py
我们发现 webtest.py 中并没有 main 函数,而是从
web.test中导入,# webtest.py from web.test import *也就是说,如果
web.test中有main函数的话,webtest.main()其实是调用web.test中的main函数。感觉~ 好神奇
web.test
看web目录下的test.py文件,果然发现了main函数,终于找到入口啦~
def main(suite=None): if not suite: main_module = __import__('__main__') # allow command line switches args = [a for a in sys.argv[1:] if not a.startswith('-')] suite = module_suite(main_module, args or None) result = runTests(suite) sys.exit(not result.wasSuccessful())把这个main函数改掉,再运行一下:
$ python test/alltests.py果然是运行修改后的函数,所以这里确定是入口。
在进入下一步之前,我们需要学习一下Python自动单元测试框架,即
Read More ...unittest模块。关于unittest,可以参考这篇文章: Python自动单元测试框架